This post explain big data vs data science which is better. Every company with or without profit generates a large amount of data for the execution of their strategies. When a large quantity of data happens in a dataset, that is called huge data. All kinds of data, structured or unstructured, in any format, can appear in huge data. Taking about information science, it is the technique of processing huge information without thinking about if the dataset is structured or disorganized. It uses algorithms and clinical techniques for the analysis of information. The main focus of information science is to draw out understanding from any big data. This post explains huge information vs data science to supply a better overview.
Big Data Vs Data Science Which Is Better Key Differences
In this article, you can know about big data vs data science which is better here are the details below;
Big information and information science are not the same, and individuals must differ by their working process and meaning. While concentrating on big data vs information science, we learned 15 important things individuals need to know to clarify why huge information and information science are interrelated but different.
1. What Do They Mean?
Some attributes can determine the dataset if huge information or not—volume figures out the amount of data, including insights of a precise event. Variety means the variation of information in a dataset. This determines the identity of information and assists in discovering more in-depth and potential details about an occasion. Speed indicates the organization’s continuous growth and determines how fast the information is being produced.
Information science is a clinical technique based program that works on huge data by utilizing its algorithm. It excerpts crucial info from numerous kinds of data and directly or indirectly takes part in the decision-making of an occasion or organization or a business that produces huge information. Information science is primarily similar to information mining as both of these audits on a database to get new, special, and essential knowledge from the dataset processing and evaluating it.
2. Big Data vs Data Science: Perception
Huge information is generally produced from different information sources. So, big information can be called a collective dataset. Every type and format of data can add in huge information, as the dataset is made with data from different sources. Structured or disorganized and even semi-structured datasets can be big information. A company or company creates real-time data that ensures an event’s existing status and helps them work appropriately towards the objective.
Information science involves different methods and tools for examining a dataset. The primary principle of data science is to streamline the intricacy of huge information. It is a theory that was made to decrease the trouble in making choices for a business. Speaking about huge information vs data science, Big data are normally unstructured and need to be streamlined, and data science is the faster option for it than the traditional applications.
3. Sources and Formation

Huge data usually a compilation of collected understanding from different sources. In many cases, data are put together from traffics on the Internet or Internet users’ usage history. Live streams, E-devices are also two main sources of data compilation. Besides, databases, stand out files, or e-commerce history plays the most major role as sources for companies. Transactions are done through emails that create crucial history for the business, and information consists of the dataset.
Data science is the scientific process that analysis information organizes them accordingly and filter undesirable and uneven unreal data from huge information. It acquires a concept about the occasion from the dataset and processes the dataset according to the business model, and creates a model using this information, collecting all the important information. It assists in activating applications, processing required information and producing models to make it work quickly and supply precision.
4. Fields of Operation
Huge data are generally needed in events where information is created continually and primarily in real-time. Huge international companies and governmental companies, mainly in focus, produce more data. Huge data works in fields associated with health, e-commerce, services, and so on. The data generation is seen in the locations where law, policy, and security concerns are also present. Telecommunication is a huge source where huge data are generated as countless history are created.
Data Science has many fields to implement its algorithms and discovers the very best result of the event. Comparing big data vs information science, browsing history on the Internet is a significant big data generation source. Information science works to discover the result such as user preferences, checked out websites, etc. It works in acknowledgment of speech or image, digital contents, spam or risk detection, and helps evaluate huge information for and from the advancement of a website.
5. Why and How
Huge information helps to bring mobility to the labor force of a company. In this world filled with competitors, a business must be combative, and without huge information, it’s inconceivable. It helps businesses to grow and get the predicted outcome out of the financial investment. With the group of information from numerous sources, it helps the authority take the next move completely, showing every possible information produced during different transactions and other including deals.
Concentrating on big information vs data science, information science is the only service to take out the findings from big information with mathematical algorithms. Another characteristic is the analytical tool that stresses the huge information to find more appropriate and accurate steps to move. Data science performs as a data visualization tool predicting the outcome, preparing a model, damaging and likewise processing data, and helping an event to provide the maximum output.
6. Big Data vs Data Science: Tools

Given that big data was first introduced in 2005 by Roger Mougalas for the business, O’Reilly Media developed numerous new and fascinating tools that process big information. As an example, we can focus on Hadoop by Apache that distributes huge information on various computers, and for this, it simply requires to follow the plain style of shows. Other tools are Apache Spark, Apache Cassandra, which work for SQL, chart procession, scalability, and so on.
Since its development, information science is working for the various business to ease the decision-making and attaching it as well. Within these years, data scientists have established the topic of data science with numerous tools. Python shows, R shows, Tableau, and Excel are some big and common examples of what information science can discuss. Statistical description and rapid growth curves with the likelihood of an event can likewise be shown with these tools.
7. Big Data vs Data Science: Impacts
Huge data has a bigger influence on businesses that were started at an early age when the term wasn’t even presented. When huge data took Walmart’s duty, where tons of items are sold on a routine basis, with a term called a retail link, the items came under a database, and every product was a single piece of information. However, it also enhances the business that creates more data, and optimal IT business are based on their information.
Data science reveals the light to any organization informing the data from an unknown pattern to known. It helps to check out more recent ways during decision making, establish processes, and broaden the revenues through item improvisation. When any incorrect comes in between any occasions, information science helps to recognize the cause and offers services sometimes. UPS shipment system uses information science to make profits and offer the very best quality customer support examining all the real-time information.
8. Platforms
In huge data vs data science, big information is usually produced from every possible history made in an event. Huge information workers find it appreciating for a business, so they began to consider smoother and much faster production of big information. As a result, different platforms started the operation of producing huge information. Enlightening examples can be Microsoft Machine Learning Server, Cloudera, DOMO, Hortonworks, Vertica, Kofax Insight, AgilOne, and much more.
Information science works to enhance a company through information analysis, process, preparation, and so on. Understanding the value and using information science, researchers started working on creating the most in-depth and precise data science platform. After several attempts, lots of platforms got produced and analyzed the defective; the next one got produced with the faulty option. For example, MATLAB, TIBCO Statistica, Anaconda, H20, R-Studio, Databricks Unified Analytics Platform, etc., are notable.
9. Relation to Cloud Computing
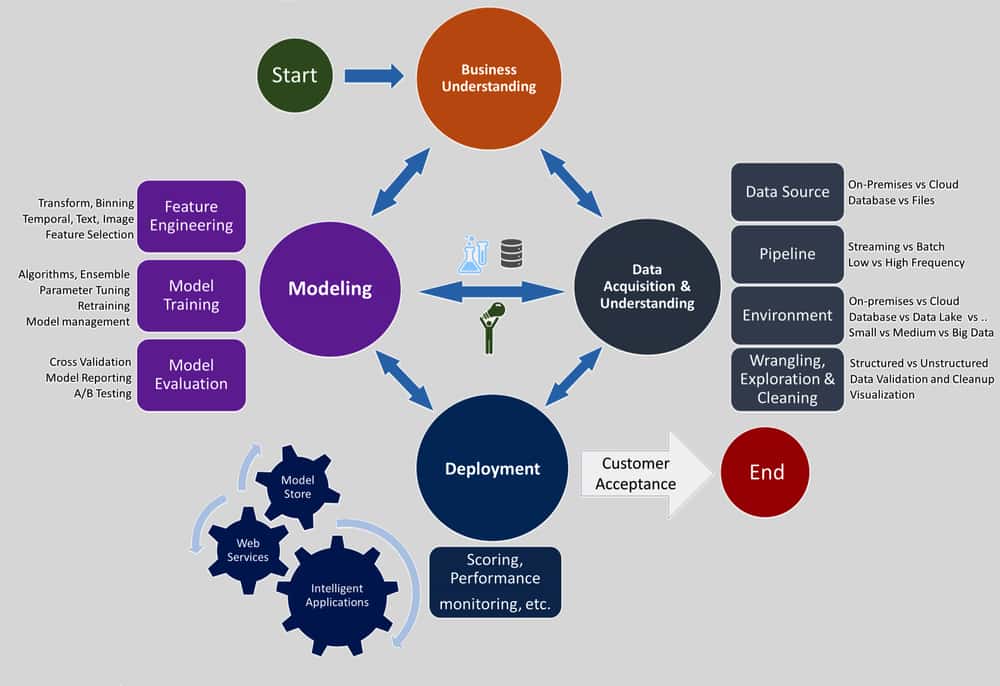
The goal of huge information is to act as CEO and attain organization success. Cloud computing’s objective is to act as CIO in supplying a convenient and accurate IT service. When the bid information and cloud computing interact, business and IT-related success come rapidly, and the performance ends up being smoother and much faster. Big information can be stored on a cloud as cloud computing provides a lot of storage and huge data needs the storage to get saved.
Working with information science requires applying algorithms to find out the accurate result and cut out unnecessary information. Not all the time, it is possible to do with regular offline computer systems. Clouds are advantaged with high computational requirements and data storage. Information science requires larger storage to save the examined data. Cloud computing is the just simpler option to this, and with its aid, the computing requirements for information analysis are also fulfilled.
10. Relation with IoT

Huge information, in general, is usually created and in a structured pattern. But when big information is produced on IoT, it is often disorganized, or sometimes you may find it semi-structured. As there are various data, essential or unnecessary, the big information is different from the regular big information, and the dataset is only functional when analyzed. According to HP, IoT will be a huge part of huge data with high-growth in volume.
Data science operates in a different on IoT based big data than the regular. Big data of IoT is generally produced in real-time. So the result that comes out is the most upgraded. Though it helps to make the very best effort with its intelligence, it’s a little more difficult to analyze the huge information without information scientists’ specialized abilities. It’s practically impossible to find out the unsegregated unneeded data from the set and process as needed.
11. Relation to Artificial Intelligence
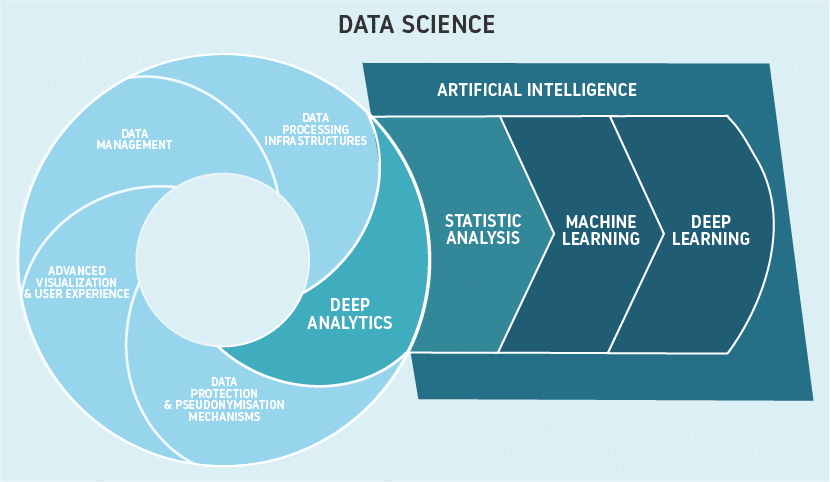
AI is much like human intelligence in the form of devices. As it works as a decision-maker, it requires generating a substantial quantity of information, and this dataset is called huge information. Huge data in Artificial intelligence are used to recognize the pattern of data circulation, assisting in identifying irregularity. Charts and probability are the research studies for understanding the status showing the relational developments, and it is just possible with real-time information generated for AI.
Data science operates where information is available, particularly big information. As AI produces big information, and the data are mainly generated in real-time, data science utilizes its algorithm. The data science tool provides a solution, choice, and outlook depending on the produced data after being analyzed. Exhibiting the IBM Watson that assists the physicians with a completely quick option based upon a client’s history. It lowers the work for the workforce.
12. Future Prospect
In the future, huge information will make a substantial distinction in every field. It will bring opportunities for the informed out of work with the post of primary information officer. Laws by different leading companies will be carried out for information security. As 93% of data stays unblemished and dealt with as unnecessary data, it will be used significantly in the coming days. However, the obstacles to keeping substantial data are coming as well.
Data science is going to be the next big giant in the coming days. It is going to make more data researchers attracting them to information science and its opportunities. Businesses are now severely in need of information scientists for the analysis of their information. The search on the Internet will be even better, smoother, and faster to the users due to the upgraded information science. Coding will be lesser for data analysis.
13. Concentrates On
Big data usually focus on technical issues. It gets created from any important or unimportant source. It extracts all the data from a source and includes it in a dataset. This is how the information ends up being big in amount, and we call it big information. When the information is generated, there is no restriction to leave out data. This primarily extracted real-time information are the primary secret for a business though most of the information stays untouched.
Information science deals with the algorithm, stats, probability, mathematics, etc. The primary focus of data science is on the decision making of a business. Companies are becoming competitive, and everyone wants to come out as a winner. Data scientists are extremely paid for the function, and they are a part of the decision-maker also. This decision-making is the main key for a service to succeed in its field, completing others.
14. Data Filtering

Big data vs information science, big data grow and bigger, and it never stops growing. However, it can assist in determining the data which are crucial and which are least crucial. This is called the information cleansing process. But as the dataset consists of big data, it is very tough to learn the spotted data and examine it independently. Though it is a harder procedure, big information assist in data cleaning up through error data detection.
Data science is utilized to discover the mistake and tidy it. When applied to huge data, data science helps in processing, examining, and outputting a final result. In this way, the summary of huge information comes out, and the unnecessary data stays untouched. These untouched data are not required any longer and can be cleaned up. And this is how information science helps keep the Internet tidy removing unnecessary, damaged information and learning the mistakes.
15. Authentication Funnel
Big information vs information science can be explained when it comes to design patterns. Before adding information to big information, the information is first identified in the data source and gets under the purification and validation test. After that, if the data is loud, it comes under-discovered, and the noise is reduced, and after that, the conversion of data occurs. Being compressed, the data gets incorporated. This is how the total style pattern of big information and how it works.
In the information science style pattern, the formulas or laws are applied to a dataset, then the issue with the information gets detected. The service to the issue that was discovered should be got for continuing to the next step. Any advantages attached to the information is discovered in the next action. Then making uses of the data need to be learned, and lastly, connecting to other designs, the sample code is implemented.
Finally, Insight
Huge data and information science are two huge giants of this period of rivals. Every service is each other’s competitor. To win in the race, one must produce meaningful information and examine it with data science for better decision making. Through this choice-making, the next relocation will to the light, and more recent extraordinary methods have been available in the light. Rapid growth will take place, and the development of the economy and IT sector will be captivating.